network jitter
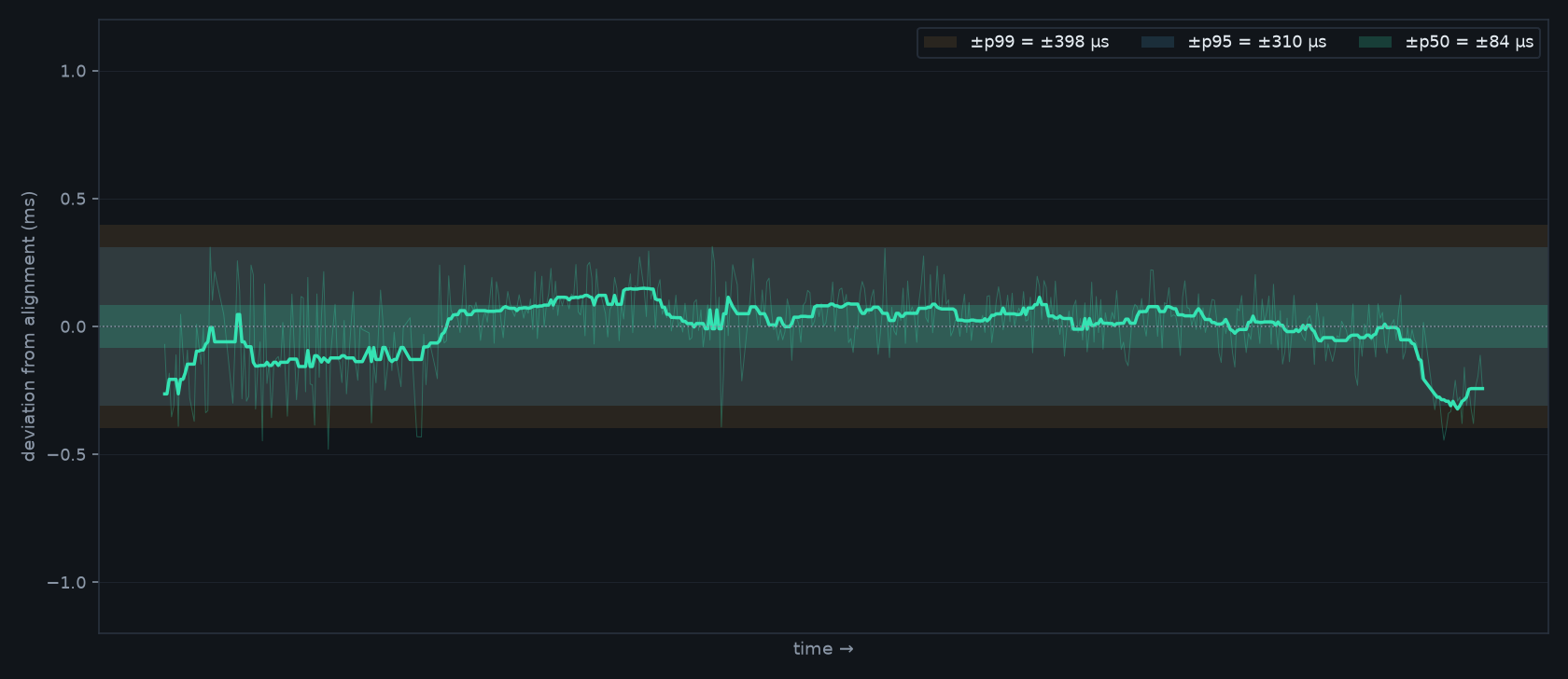
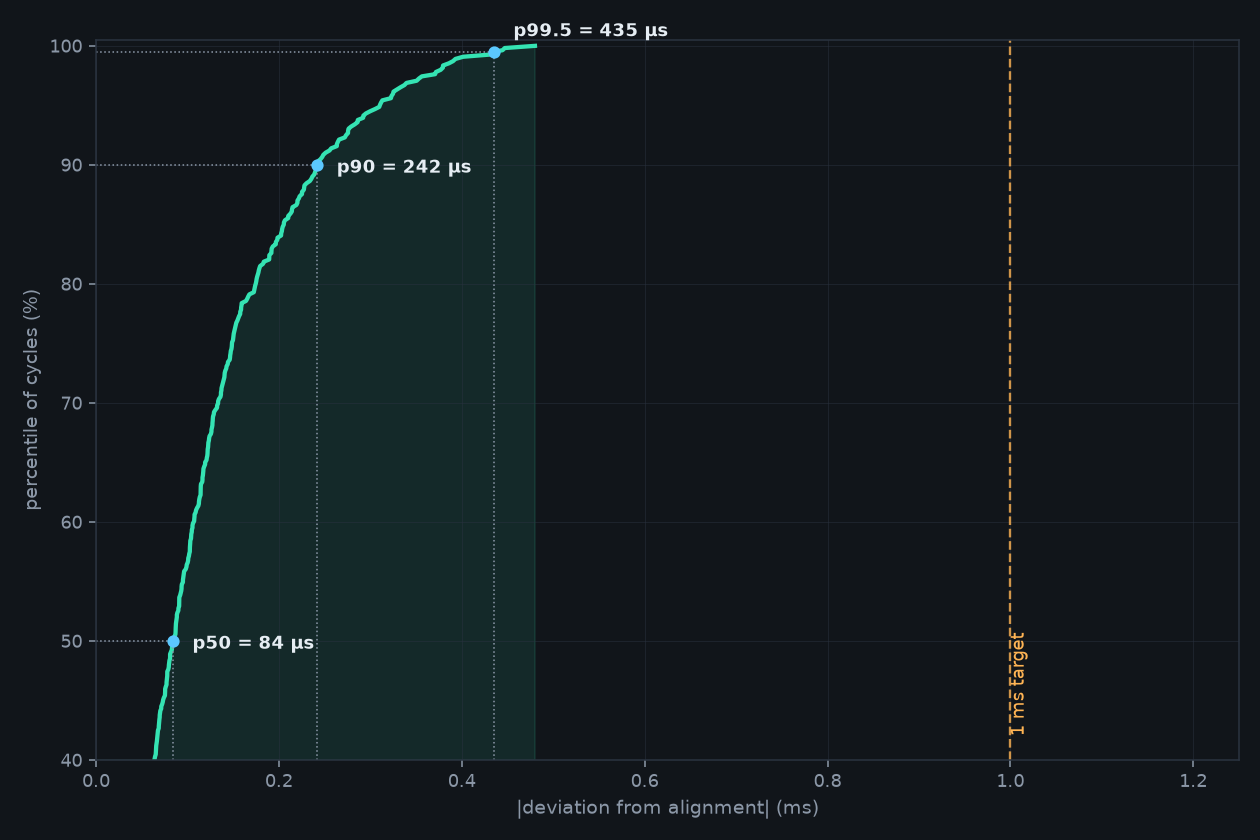
Wi-Fi delivers packets in bursts and at uneven intervals — played naively, audio stutters and rooms drift apart.
→Every frame is stamped with a presentation time and played at that exact deadline against a shared clock. A small per-group playout buffer absorbs the jitter, so output stays smooth and every room hits the same instant.
packet loss
On a busy network UDP datagrams simply vanish, and a dropped frame is an audible click or gap.
→Audio is Opus-coded so each frame fits one small packet (no fragile IP fragmentation), and the master sends forward-error-correction parity alongside it, so most lost frames are rebuilt with no retransmit. A TCP transport is one toggle away when you'd rather trade a little latency for certainty.
system clock drift
No two devices agree on what time it is — their clocks start at different offsets and tick at slightly different rates.
→One node is the time reference. Each player continuously measures its offset and round-trip to that master and translates “play at T” into its own local time, so the same frame lands at the same real-world instant on every speaker.
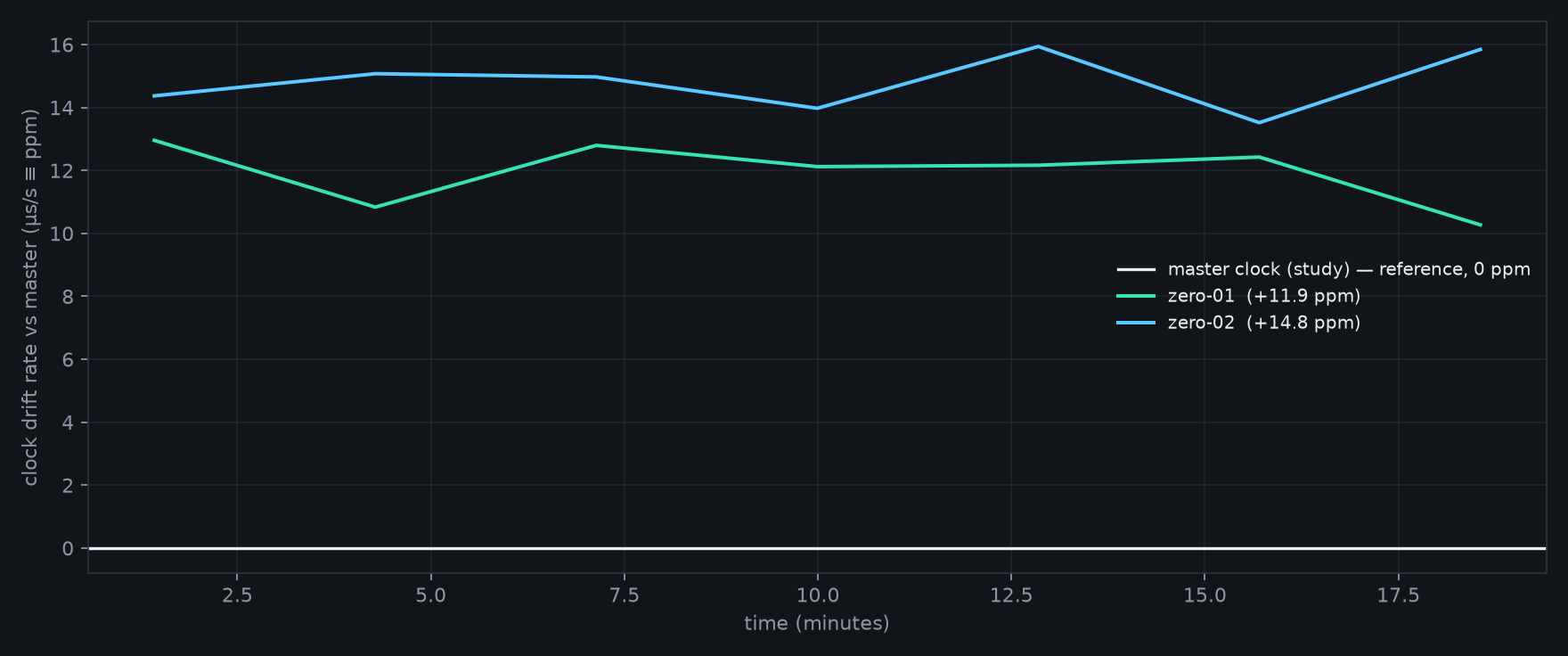
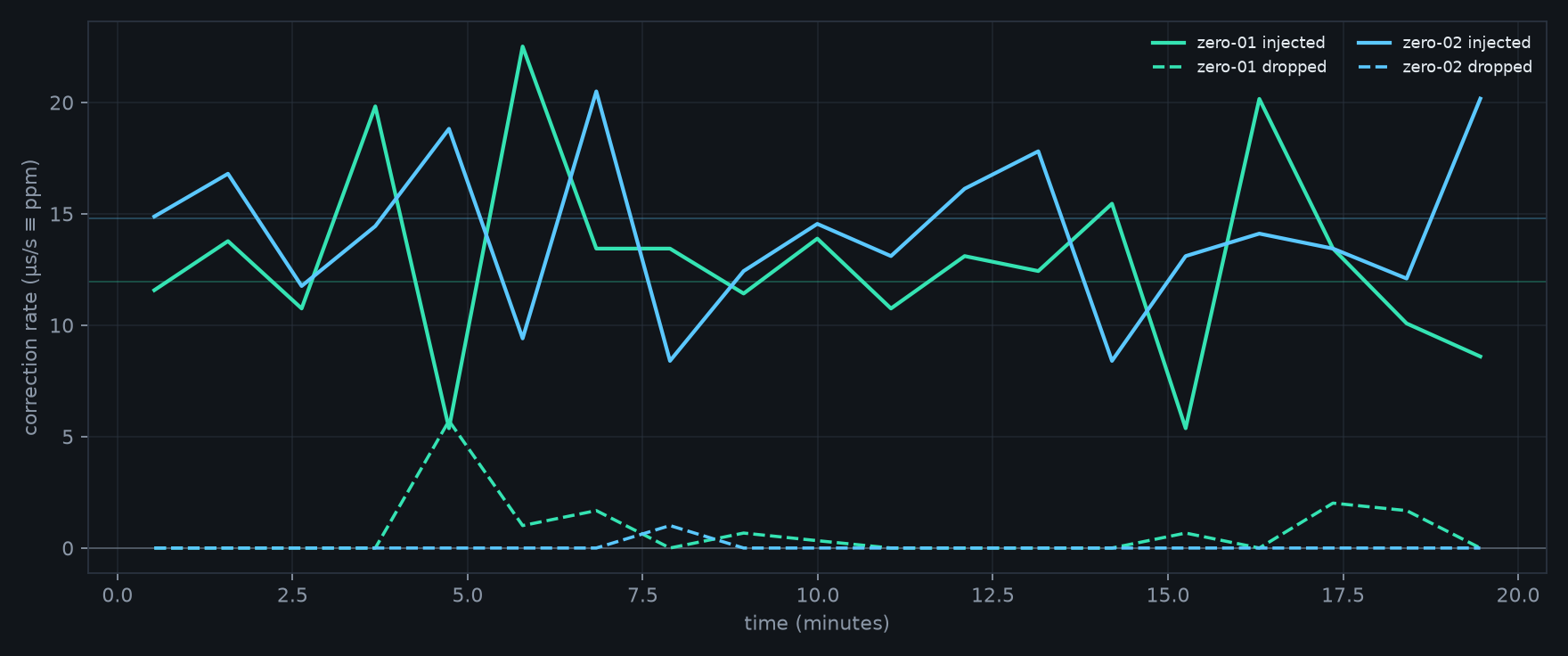
DAC clock drift
Even with perfect timing, no two sound cards sample at exactly 48 kHz — a few parts-per-million apart, rooms slide out of phase over a long track.
→A continuous rate servo watches how fast each DAC actually drains its buffer versus the master timeline and resamples by a micro-correction to match. Rooms stay phase-locked for hours, not just for the first minute.